



Next: One-Dimensional Matrix-Vector Multiplication
Up: Introduction to Parallel Algorithms
Previous: Odd-Even Sort
Contents
Cannon's Matrix-Matrix Multiplication with MPI's Topologies
- To illustrate how the various topology functions are used.
- Cannon's algorithm views the processes as being arranged in a virtual two-dimensional square array. It uses this array to distribute the matrices
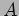 ,
, 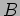 , and the result matrix
, and the result matrix 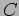 in a block fashion.
in a block fashion.
- That is, if
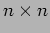 is the size of each matrix and
is the size of each matrix and 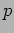 is the total number of process, then each matrix is divided into square blocks of size
is the total number of process, then each matrix is divided into square blocks of size
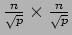 (assuming that is a perfect square).
(assuming that is a perfect square).
- Now, process
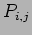 in the grid is assigned the
in the grid is assigned the
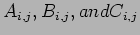 blocks of each matrix.
blocks of each matrix.
- After an initial data alignment phase, the algorithm proceeds in
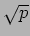 steps. In each step, every process multiplies the locally available blocks of matrices and , and then sends the block of to the leftward process, and the block of to the upward process.
steps. In each step, every process multiplies the locally available blocks of matrices and , and then sends the block of to the leftward process, and the block of to the upward process.
- The following http://siber.cankaya.edu.tr/ParallelComputing/cfiles/cmmm.c code segment shows the MPI function that implements Cannon's algorithm.
- The dimension of the matrices is supplied in the parameter
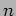 . The parameters
. The parameters 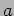 ,
, 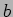 , and
, and 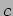 point to the locally stored portions of the matrices , , and , respectively.
point to the locally stored portions of the matrices , , and , respectively.
- The size of these arrays is
, where is the number of processes. This routine assumes that is a perfect square and that is a multiple of .
- The parameter
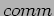 stores the communicator describing the processes that call the MatrixMatrixMultiply function.
stores the communicator describing the processes that call the MatrixMatrixMultiply function.
1 MatrixMatrixMultiply(int n, double *a, double *b, double *c,
2 MPI_Comm comm)
3 {
4 int i;
5 int nlocal;
6 int npes, dims[2], periods[2];
7 int myrank, my2drank, mycoords[2];
8 int uprank, downrank, leftrank, rightrank, coords[2];
9 int shiftsource, shiftdest;
10 MPI_Status status;
11 MPI_Comm comm_2d;
12
13 /* Get the communicator related information */
14 MPI_Comm_size(comm, &npes);
15 MPI_Comm_rank(comm, &myrank);
16
17 /* Set up the Cartesian topology */
18 dims[0] = dims[1] = sqrt(npes);
19
20 /* Set the periods for wraparound connections */
21 periods[0] = periods[1] = 1;
22
23 /* Create the Cartesian topology, with rank reordering */
24 MPI_Cart_create(comm, 2, dims, periods, 1, &comm_2d);
25
26 /* Get the rank and coordinates with respect to the new topology */
27 MPI_Comm_rank(comm_2d, &my2drank);
28 MPI_Cart_coords(comm_2d, my2drank, 2, mycoords);
29
30 /* Compute ranks of the up and left shifts */
31 MPI_Cart_shift(comm_2d, 0, -1, &rightrank, &leftrank);
32 MPI_Cart_shift(comm_2d, 1, -1, &downrank, &uprank);
33
34 /* Determine the dimension of the local matrix block */
35 nlocal = n/dims[0];
36
37 /* Perform the initial matrix alignment. First for A and then for B */
38 MPI_Cart_shift(comm_2d, 0, -mycoords[0], &shiftsource, &shiftdest);
39 MPI_Sendrecv_replace(a, nlocal*nlocal, MPI_DOUBLE, shiftdest,
40 1, shiftsource, 1, comm_2d, &status);
41
42 MPI_Cart_shift(comm_2d, 1, -mycoords[1], &shiftsource, &shiftdest);
43 MPI_Sendrecv_replace(b, nlocal*nlocal, MPI_DOUBLE,
44 shiftdest, 1, shiftsource, 1, comm_2d, &status);
45
46 /* Get into the main computation loop */
47 for (i=0; i<dims[0]; i++) {
48 MatrixMultiply(nlocal, a, b, c); /*c=c+a*b*/
49
50 /* Shift matrix a left by one */
51 MPI_Sendrecv_replace(a, nlocal*nlocal, MPI_DOUBLE,
52 leftrank, 1, rightrank, 1, comm_2d, &status);
53
54 /* Shift matrix b up by one */
55 MPI_Sendrecv_replace(b, nlocal*nlocal, MPI_DOUBLE,
56 uprank, 1, downrank, 1, comm_2d, &status);
57 }
58
59 /* Restore the original distribution of a and b */
60 MPI_Cart_shift(comm_2d, 0, +mycoords[0], &shiftsource, &shiftdest);
61 MPI_Sendrecv_replace(a, nlocal*nlocal, MPI_DOUBLE,
62 shiftdest, 1, shiftsource, 1, comm_2d, &status);
63
64 MPI_Cart_shift(comm_2d, 1, +mycoords[1], &shiftsource, &shiftdest);
65 MPI_Sendrecv_replace(b, nlocal*nlocal, MPI_DOUBLE,
66 shiftdest, 1, shiftsource, 1, comm_2d, &status);
67
68 MPI_Comm_free(&comm_2d); /* Free up communicator */
69 }
70
71 /* This function performs a serial matrix-matrix multiplication c = a*b */
72 MatrixMultiply(int n, double *a, double *b, double *c)
73 {
74 int i, j, k;
75
76 for (i=0; i<n; i++)
77 for (j=0; j<n; j++)
78 for (k=0; k<n; k++)
79 c[i*n+j] += a[i*n+k]*b[k*n+j];
80 }
- The following http://siber.cankaya.edu.tr/ParallelComputing/cfiles/cnbmmm.c code segment shows the MPI program that implements Cannon's algorithm using non-blocking send and receive operations. The various parameters are identical to those of the previous blocking version.
1 MatrixMatrixMultiply_NonBlocking(int n, double *a, double *b,
2 double *c, MPI_Comm comm)
3 {
4 int i, j, nlocal;
5 double *a_buffers[2], *b_buffers[2];
6 int npes, dims[2], periods[2];
7 int myrank, my2drank, mycoords[2];
8 int uprank, downrank, leftrank, rightrank, coords[2];
9 int shiftsource, shiftdest;
10 MPI_Status status;
11 MPI_Comm comm_2d;
12 MPI_Request reqs[4];
13
14 /* Get the communicator related information */
15 MPI_Comm_size(comm, &npes);
16 MPI_Comm_rank(comm, &myrank);
17
18 /* Set up the Cartesian topology */
19 dims[0] = dims[1] = sqrt(npes);
20
21 /* Set the periods for wraparound connections */
22 periods[0] = periods[1] = 1;
23
24 /* Create the Cartesian topology, with rank reordering */
25 MPI_Cart_create(comm, 2, dims, periods, 1, &comm_2d);
26
27 /* Get the rank and coordinates with respect to the new topology */
28 MPI_Comm_rank(comm_2d, &my2drank);
29 MPI_Cart_coords(comm_2d, my2drank, 2, mycoords);
30
31 /* Compute ranks of the up and left shifts */
32 MPI_Cart_shift(comm_2d, 0, -1, &rightrank, &leftrank);
33 MPI_Cart_shift(comm_2d, 1, -1, &downrank, &uprank);
34
35 /* Determine the dimension of the local matrix block */
36 nlocal = n/dims[0];
37
38 /* Setup the a_buffers and b_buffers arrays */
39 a_buffers[0] = a;
40 a_buffers[1] = (double *)malloc(nlocal*nlocal*sizeof(double));
41 b_buffers[0] = b;
42 b_buffers[1] = (double *)malloc(nlocal*nlocal*sizeof(double));
43
44 /* Perform the initial matrix alignment. First for A and then for B */
45 MPI_Cart_shift(comm_2d, 0, -mycoords[0], &shiftsource, &shiftdest);
46 MPI_Sendrecv_replace(a_buffers[0], nlocal*nlocal, MPI_DOUBLE,
47 shiftdest, 1, shiftsource, 1, comm_2d, &status);
48
49 MPI_Cart_shift(comm_2d, 1, -mycoords[1], &shiftsource, &shiftdest);
50 MPI_Sendrecv_replace(b_buffers[0], nlocal*nlocal, MPI_DOUBLE,
51 shiftdest, 1, shiftsource, 1, comm_2d, &status);
52
53 /* Get into the main computation loop */
54 for (i=0; i<dims[0]; i++) {
55 MPI_Isend(a_buffers[i%2], nlocal*nlocal, MPI_DOUBLE,
56 leftrank, 1, comm_2d, &reqs[0]);
57 MPI_Isend(b_buffers[i%2], nlocal*nlocal, MPI_DOUBLE,
58 uprank, 1, comm_2d, &reqs[1]);
59 MPI_Irecv(a_buffers[(i+1)%2], nlocal*nlocal, MPI_DOUBLE,
60 rightrank, 1, comm_2d, &reqs[2]);
61 MPI_Irecv(b_buffers[(i+1)%2], nlocal*nlocal, MPI_DOUBLE,
62 downrank, 1, comm_2d, &reqs[3]);
63
64 /* c = c + a*b */
65 MatrixMultiply(nlocal, a_buffers[i%2], b_buffers[i%2], c);
66
67 for (j=0; j<4; j++)
68 MPI_Wait(&reqs[j], &status);
69 }
70
71 /* Restore the original distribution of a and b */
72 MPI_Cart_shift(comm_2d, 0, +mycoords[0], &shiftsource, &shiftdest);
73 MPI_Sendrecv_replace(a_buffers[i%2], nlocal*nlocal, MPI_DOUBLE,
74 shiftdest, 1, shiftsource, 1, comm_2d, &status);
75
76 MPI_Cart_shift(comm_2d, 1, +mycoords[1], &shiftsource, &shiftdest);
77 MPI_Sendrecv_replace(b_buffers[i%2], nlocal*nlocal, MPI_DOUBLE,
78 shiftdest, 1, shiftsource, 1, comm_2d, &status);
79
80 MPI_Comm_free(&comm_2d); /* Free up communicator */
81
82 free(a_buffers[1]);
83 free(b_buffers[1]);
84 }
Next: One-Dimensional Matrix-Vector Multiplication
Up: Introduction to Parallel Algorithms
Previous: Odd-Even Sort
Contents
Cem Ozdogan
2006-12-27