



Next: Message Passing vs Shared
Up: Message Passing Architecture
Previous: Processor Support for Message
Contents
Example Message Passing Architectures
- Examples of message passing machines include Caltech Hypercube, the Inmos Transputer systems, Meiko CS-2, Cosmic Cube, nCUBE/2, iPSC/2, iPSC/860, CM-5. Other recent systems include the IBM Scalable Power Series (IBM POWERparallel 3, SP 3).
- The Caltech Hypercube (the Cosmic Cube) was an
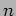 -dimensional hypercube system with a single host, known as the Intermediate Host (IH), for global control. The original system was based on the simple store-and-forward routing mechanism. The system started with a set of routine libraries known as the crystalline operating system (CrOS), which supported C and FORTRAN. The system supported only collective operations (broadcast) to/from the IH. Two years later, the Caltech project
team introduced a hardware wormhole routing chip.
-dimensional hypercube system with a single host, known as the Intermediate Host (IH), for global control. The original system was based on the simple store-and-forward routing mechanism. The system started with a set of routine libraries known as the crystalline operating system (CrOS), which supported C and FORTRAN. The system supported only collective operations (broadcast) to/from the IH. Two years later, the Caltech project
team introduced a hardware wormhole routing chip.
- The Cosmic Cube is considered the first working hypercube multicomputer message passing system. The Cosmic cube system has been constructed using 64 node for the Intel iPSC. Each node has 128 KB of dynamic RAM that has parity checking for error detection but no correction. In addition, each node has 8 KB of ROM in order to store the initialization and bootstrap programs. The basic packet size is 64 bits
with queues in each node. In this system, messages are communicated via transmissions (send/receive).
- The Meiko Computing Surface CS-1 was the first Inmos Transputer T800-based system. The Transputer was a 32-bit microprocessor with fast task-switching capability through hardware intercommunication. The system was programmed using a communication sequential processes (CSP) language called Occam. The language used abstract links known as channels and supported synchronous blocking send and receive primitives.
- The Intel iPSC is a commercial message passing hypercube developed after the Cosmic Cube. The iPSC/1 used Intel 286 processors with a 287 floating-point coprocessor. Each node consists of a single board computer having two buses, a process bus and I/O bus. Nodes are controlled by the Cube manager. Each node has seven communication channels (links) to communicate with other nodes and a separate channel for communication with the Cube Manager. FORTRAN message passing routines are supported. The software environment used in iPSC1 was called NX1, and has a more distributed processes environment than those included in the Caltech CrOS.
- The nCUBE/2 has up to a few thousand nodes connected in a binary hypercube network. Each node consists of a CPU-chip and DRAM chips on a small double-sided printed circuit board. The CPU chip contains a 64 bit integer unit, an IEEE floating-point unit, a DRAM memory interface, a network interface with 28 DMA channels, and routers that support cut-through routing across a 13-dimensional hypercube. The processor runs at 20 MHz and delivers roughly 5 MIPS or 1.5 MFLOPS.
- The Thinking Machine CM-5 had up to a few thousand nodes interconnected in a hypertree (incomplete fat tree). Each node consists of a 33 MHz SPARC RISC processor chip-set, local DRAM memory, and a network interface to the hypertree and broadcast/scan/prefix control networks. Compared to its predecessors, CM-5 represented a true distributed memory message passing system. It featured two interconnection networks, and Sparc-based processing nodes. Each node has four vector units for pipeline arithmetic operations. The CM-5 programming environment consisted of the CMOST operating system, the CMMD message passing library, and various array-style compilers. The latter includes CMF, supporting a F90-like SIMD programming style.
- The IBM Scalable POWERparallel 3 (SP 3) is the most recent IBM supercomputer series (1999/2000). The SP 3 consists of 2 to 512 POWER3 Architecture RISC System/6000 processor nodes. Each node has its own private memory and its own copy of the AIX operating system. The POWER3 processor is an eight-stage pipeline processor. Two instructions can be executed per clock-cycle except for the multiply and divide. A multiply instruction takes two clock cycles while a divide instruction takes 13 to
17 cycles. The FPU contains two execution units using double precision (64 bit). Both execution units are identical and conform to the IEEE 754 binary floating-point standard.
Figure 6.6:
Typical SP 3 node.
|
|
- Figure 6.6 shows a block diagram of a typical SP 3 node. Nodes are connected by a high-performance scalable packet-switched network in
a distributed memory and message passing.
- The network's building block is a two-staged
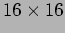 switch board, made up of
switch board, made up of
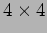 bidirectional crossbar switching
elements (SEs).
bidirectional crossbar switching
elements (SEs).
- Each link is bidirectional and has a 40 MB/s bandwidth in each direction. The switch uses buffered cut-through wormhole routing. This interconnection arrangement allows all processors to send messages simultaneously.
- For full connectivity, at least one extra stage is provided. This stage guarantees that there are at least four different paths between every pair of nodes. This form of path redundancy helps in reducing network congestion as well as recovery in the presence of failures.
- The communication protocol supports end-to-end packet acknowledgment. For every packet sent by a source node, there is a returned acknowledgment after the packet has reached the destination node. This allows source nodes to discover packet loss. Automatic retransmission of a packet is made if the acknowledgment is not received within a preset time interval.
Next: Message Passing vs Shared
Up: Message Passing Architecture
Previous: Processor Support for Message
Contents
Cem Ozdogan
2006-12-27
![\includegraphics[scale=0.8]{figures/sp3.ps}](img260.png)