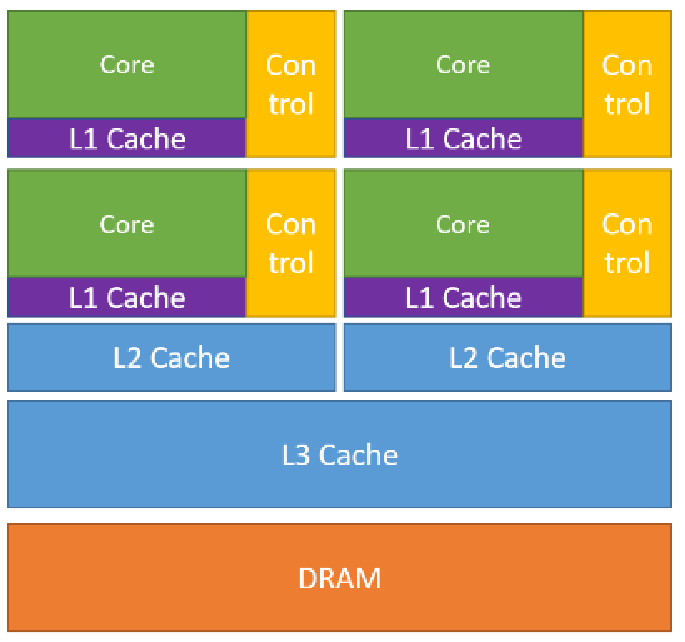
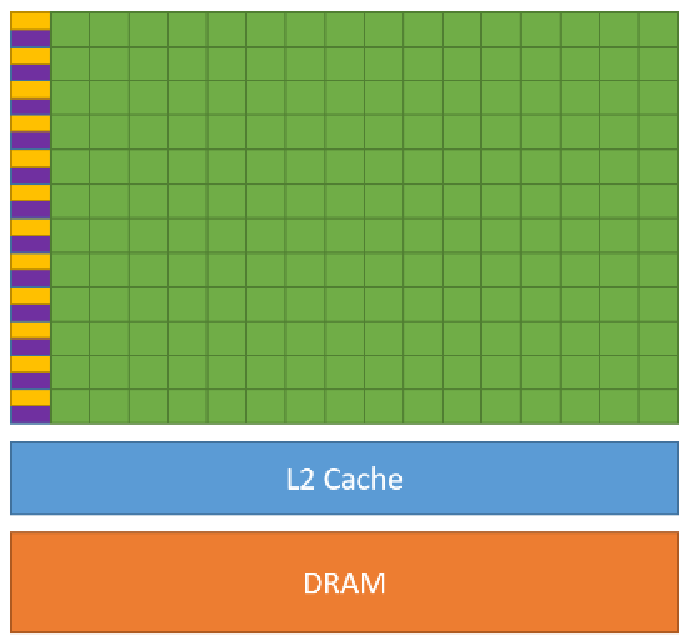
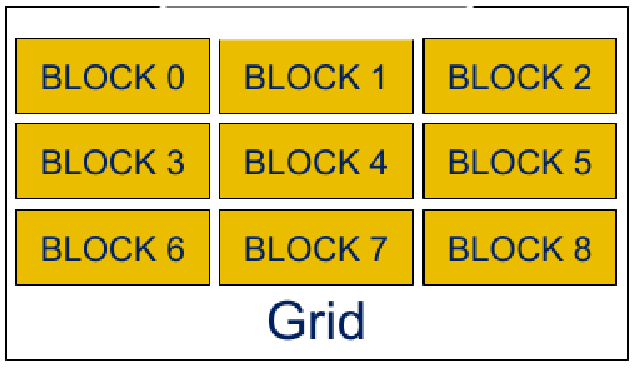
Next: Execution and Programming Models Up: GPU parallelization Previous: GPU parallelization Contents
|
|
| 1 | GPU Programming API: CUDA (Compute Unified Device Architecture) : parallel GPU programming API created by NVIDA
|
| 2 | GPU Programming API: OpenGL - an open standard for GPU programming. |
| 3 | GPU Programming API: DirectX - a series of Microsoft multimedia programming interfaces. https://developer.nvidia.com/ Download: CUDA Toolkit, NVIDIA HPC SDK (Software Development Kit) |
|
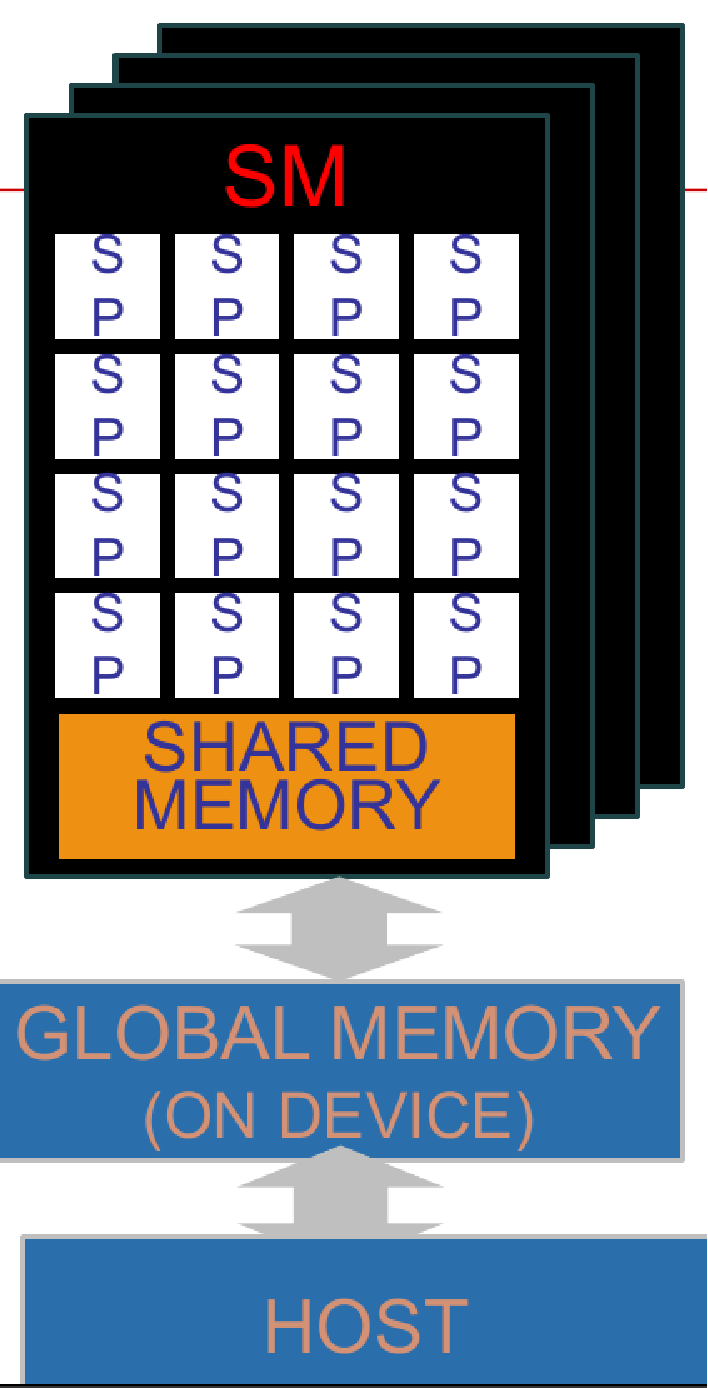
|
|
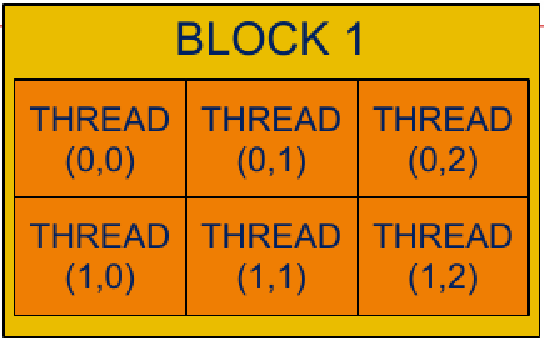
|
|
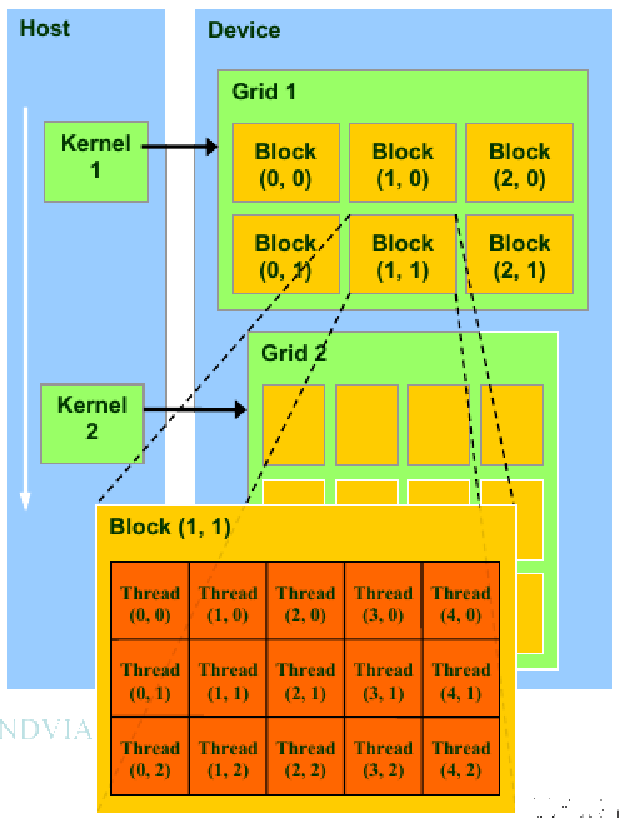
|