Next: Hands-on; GPU parallelization Up: GPU parallelization Previous: Exploring the GPU Architecture Contents
__host__, __global__, __device__
__global__ void cuda_hello(){
}
|
compute <<<gs,bs>>>(<args>)
cuda_hello <<<blocks_per_grid,threads_per_block>>> (); |
__shared__, __device__, __constant__, ...
__device__ const char *STR = "HELLO WORLD!"; |
cudaMemcpy(h_obj,d_obj, cudaMemcpyDevicetoHost)
cudaMemcpy( d_a, h_a, bytes, cudaMemcpyHostToDevice); cudaMemcpy( h_c, d_c, bytes, cudaMemcpyDeviceToHost ); |
__synchthreads()
cudaDeviceSynchronize(); |
__global__tells the compiler nvcc to make a function a kernel (and compile/run it for the GPU, instead of the CPU)
 ).
).
1 double *h_a; // Host input vectors
2 double *d_a; // Device input vectors
3 h_a = (double*)malloc(bytes); // Allocate memory for each vector on host
4 cudaMalloc(&d_a, bytes); // Allocate memory for each vector on GPU
5 cudaMemcpy( d_a, h_a, bytes, cudaMemcpyHostToDevice); // Copy data from host array h_a to device arrays d_a
6 add_vectors<<<blk_in_grid, thr_per_blk>>>(d_a, d_b, d_c); // Execute the kernel
7 cudaMemcpy( h_c, d_c, bytes, cudaMemcpyDeviceToHost ); // Copy data from device array d_c to host array h_c
|
|
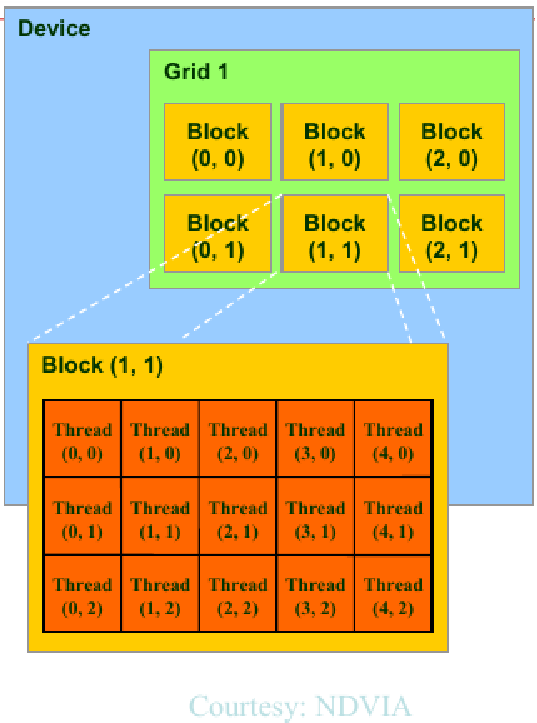
|
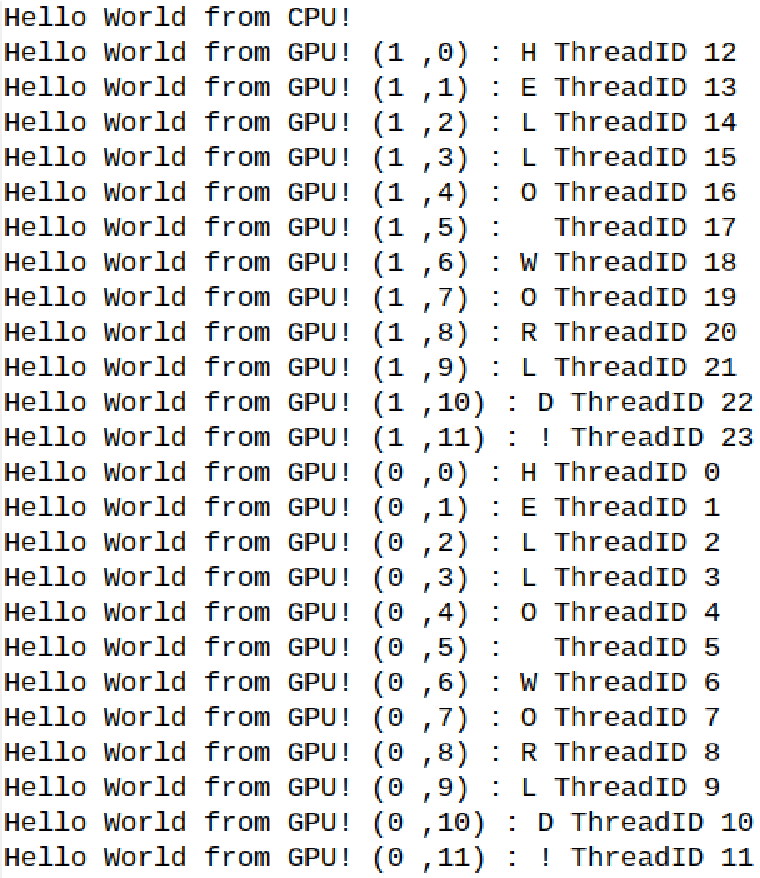
1 #include <stdio.h>
2 #include <unistd.h>
3 __device__ const char *STR = "HELLO WORLD!";
4 const int STR_LENGTH = 12;
5 __global__ void cuda_hello(){
6 // blockIdx.x: Block index within the grid in x-direction
7 // threadIdx.x: Thread index within the block
8 // blockDim.x: # of threads in a block
9 printf("Hello World from GPU! (%d ,%d) : %c ThreadID %d \n", blockIdx.x, threadIdx.x, STR[threadIdx.x % STR_LENGTH], (threadIdx.x +blockIdx.x*blockDim.x));
10 }
11 int main() {
12 printf("Hello World from CPU!\n");
13 sleep(2);
14 int threads_per_block=12;
15 int blocks_per_grid=2;
16 cuda_hello <<<blocks_per_grid,threads_per_block>>> ();
17 cudaDeviceSynchronize(); /* Halt host thread execution on CPU until the device has finished processing all previously requested tasks */
18 return 0;
19 }
|
1 #include <stdio.h>
2 #include <cuda.h>
3 #include <cuda_runtime.h>
4
5 // Note: Needs compute capability >= 2.0, so compile with:
6 // nvcc helloWorld.cu -arch=compute_20 -code=sm_20,compute_20 -o helloWorld
7
8 #define N 720 // number of computations
9 #define GRID_D1 20 // constants for grid and block sizes
10 #define GRID_D2 3 // constants for grid and block sizes
11 #define BLOCK_D1 12 // constants for grid and block sizes
12 #define BLOCK_D2 1 // constants for grid and block sizes
13 #define BLOCK_D3 1 // constants for grid and block sizes
14
15 __global__ void hello(void) // this is the kernel function called for each thread
16 {
17 // CUDA variables {threadIdx, blockIdx, blockDim, gridDim} to determine a unique thread ID
18 int myblock = blockIdx.x + blockIdx.y * gridDim.x; // id of the block
19 int blocksize = blockDim.x * blockDim.y * blockDim.z; // size of each block
20 int subthread = threadIdx.z*(blockDim.x * blockDim.y) + threadIdx.y*blockDim.x + threadIdx.x; // id of thread in a given block
21 int idx = myblock * blocksize + subthread; // assign overall id/index of the thread
22 int nthreads=blocksize*gridDim.x*gridDim.y; // Total # of threads
23 int chunk=20; // Vary this value to see the changes at the output
24 if(idx < chunk || idx > nthreads-chunk) { // only print first and last chunks of threads
25 if (idx < N){
26 printf("Hello world! My block index is (%d,%d) [Grid dims=(%d,%d)], 3D-thread index within block=(%d,%d,%d) => thread index=%d \n", blockIdx.x, blockIdx.y, gridDim.x, gridDim.y, threadIdx.x, threadIdx.y, threadIdx.z, idx);
27 }
28 else
29 {
30 printf("Hello world! My block index is (%d,%d) [Grid dims=(%d,%d)], 3D-thread index within block=(%d,%d,%d) => thread index=%d [### this thread would not be used for N=%d ###]\n", blockIdx.x, blockIdx.y, gridDim.x, gridDim.y, threadIdx.x, threadIdx.y, threadIdx.z, idx, N);
31 }
32 }
33 }
|
30 int main(int argc,char **argv)
31 {
32 // objects containing the block and grid info
33 const dim3 blockSize(BLOCK_D1, BLOCK_D2, BLOCK_D3);
34 const dim3 gridSize(GRID_D1, GRID_D2, 1);
35 int nthreads = BLOCK_D1*BLOCK_D2*BLOCK_D3*GRID_D1*GRID_D2; // Total # of threads
36 if (nthreads < N){
37 printf("\n============ NOT ENOUGH THREADS TO COVER N=%d ===============\n\n",N);
38 }
39 else
40 {
41 printf("Launching %d threads (N=%d)\n",nthreads,N);
42 }
43 hello<<<gridSize, blockSize>>>(); // launch the kernel on the specified grid of thread blocks
44 cudaError_t cudaerr = cudaDeviceSynchronize(); // Need to flush prints, otherwise none of the prints from within the kernel will show up as program exit does not flush the print buffer
45 if (cudaerr){
46 printf("kernel launch failed with error \"%s\".\n",
47 cudaGetErrorString(cudaerr));
48 }
49 else
50 {
51 printf("kernel launch success!\n");
52 }
53 printf("That's all!\n");
54 return 0;
55 }
|
