



Next: Examples; Parallel Algorithms
Up: Introduction to Parallel Algorithms
Previous: One-Dimensional Matrix-Vector Multiplication
Contents
Two-Dimensional Matrix-Vector Multiplication
- An alternative way of distributing matrix
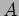 is to use a two-dimensional distribution, giving rise to the two-dimensional parallel formulations of the matrix-vector multiplication algorithm.
is to use a two-dimensional distribution, giving rise to the two-dimensional parallel formulations of the matrix-vector multiplication algorithm.
- The following http://siber.cankaya.edu.tr/ParallelComputing/cfiles/tdmvm.c code segment shows how these topologies and their partitioning are used to implement the two-dimensional matrix-vector multiplication.
- The dimension of the matrix is supplied in the parameter
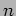 , the parameters
, the parameters 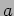 and
and 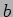 point to the locally stored portions of matrix and vector , respectively, and the parameter
point to the locally stored portions of matrix and vector , respectively, and the parameter 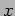 points to the local portion of the output matrix-vector product.
points to the local portion of the output matrix-vector product.
- Note that only the processes along the first column of the process grid will store initially, and that upon return, the same set of processes will store the result . For simplicity, the program assumes that the number of processes
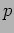 is a perfect square and that is a multiple of
is a perfect square and that is a multiple of 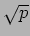 .
.
1 MatrixVectorMultiply_2D(int n, double *a, double *b, double *x,
2 MPI_Comm comm)
3 {
4 int ROW=0, COL=1; /* Improve readability */
5 int i, j, nlocal;
6 double *px; /* Will store partial dot products */
7 int npes, dims[2], periods[2], keep_dims[2];
8 int myrank, my2drank, mycoords[2];
9 int other_rank, coords[2];
10 MPI_Status status;
11 MPI_Comm comm_2d, comm_row, comm_col;
12
13 /* Get information about the communicator */
14 MPI_Comm_size(comm, &npes);
15 MPI_Comm_rank(comm, &myrank);
16
17 /* Compute the size of the square grid */
18 dims[ROW] = dims[COL] = sqrt(npes);
19
20 nlocal = n/dims[ROW];
21
22 /* Allocate memory for the array that will hold the partial dot-products */
23 px = malloc(nlocal*sizeof(double));
24
25 /* Set up the Cartesian topology and get the rank & coordinates of the process in
this topology */
26 periods[ROW] = periods[COL] = 1; /* Set the periods for wrap-around connections */
27
28 MPI_Cart_create(MPI_COMM_WORLD, 2, dims, periods, 1, &comm_2d);
29
30 MPI_Comm_rank(comm_2d, &my2drank); /* Get my rank in the new topology */
31 MPI_Cart_coords(comm_2d, my2drank, 2, mycoords); /* Get my coordinates */
32
33 /* Create the row-based sub-topology */
34 keep_dims[ROW] = 0;
35 keep_dims[COL] = 1;
36 MPI_Cart_sub(comm_2d, keep_dims, &comm_row);
37
38 /* Create the column-based sub-topology */
39 keep_dims[ROW] = 1;
40 keep_dims[COL] = 0;
41 MPI_Cart_sub(comm_2d, keep_dims, &comm_col);
42
43 /* Redistribute the b vector. */
44 /* Step 1. The processors along the 0th column send their data to the diagonal
processors */
45 if (mycoords[COL] == 0 && mycoords[ROW] != 0) { /* I'm in the first column */
46 coords[ROW] = mycoords[ROW];
47 coords[COL] = mycoords[ROW];
48 MPI_Cart_rank(comm_2d, coords, &other_rank);
49 MPI_Send(b, nlocal, MPI_DOUBLE, other_rank, 1, comm_2d);
50 }
51 if (mycoords[ROW] == mycoords[COL] && mycoords[ROW] != 0) {
52 coords[ROW] = mycoords[ROW];
53 coords[COL] = 0;
54 MPI_Cart_rank(comm_2d, coords, &other_rank);
55 MPI_Recv(b, nlocal, MPI_DOUBLE, other_rank, 1, comm_2d,
56 &status);
57 }
58
59 /* Step 2. The diagonal processors perform a column-wise broadcast */
60 coords[0] = mycoords[COL];
61 MPI_Cart_rank(comm_col, coords, &other_rank);
62 MPI_Bcast(b, nlocal, MPI_DOUBLE, other_rank, comm_col);
63
64 /* Get into the main computational loop */
65 for (i=0; i<nlocal; i++) {
66 px[i] = 0.0;
67 for (j=0; j<nlocal; j++)
68 px[i] += a[i*nlocal+j]*b[j];
69 }
70
71 /* Perform the sum-reduction along the rows to add up the partial dot-products */
72 coords[0] = 0;
73 MPI_Cart_rank(comm_row, coords, &other_rank);
74 MPI_Reduce(px, x, nlocal, MPI_DOUBLE, MPI_SUM, other_rank,
75 comm_row);
76
77 MPI_Comm_free(&comm_2d); /* Free up communicator */
78 MPI_Comm_free(&comm_row); /* Free up communicator */
79 MPI_Comm_free(&comm_col); /* Free up communicator */
80
81 free(px);
82 }
Next: Examples; Parallel Algorithms
Up: Introduction to Parallel Algorithms
Previous: One-Dimensional Matrix-Vector Multiplication
Contents
Cem Ozdogan
2006-12-27